Smart-Cache DOCUMENTS
(closed source) BETA
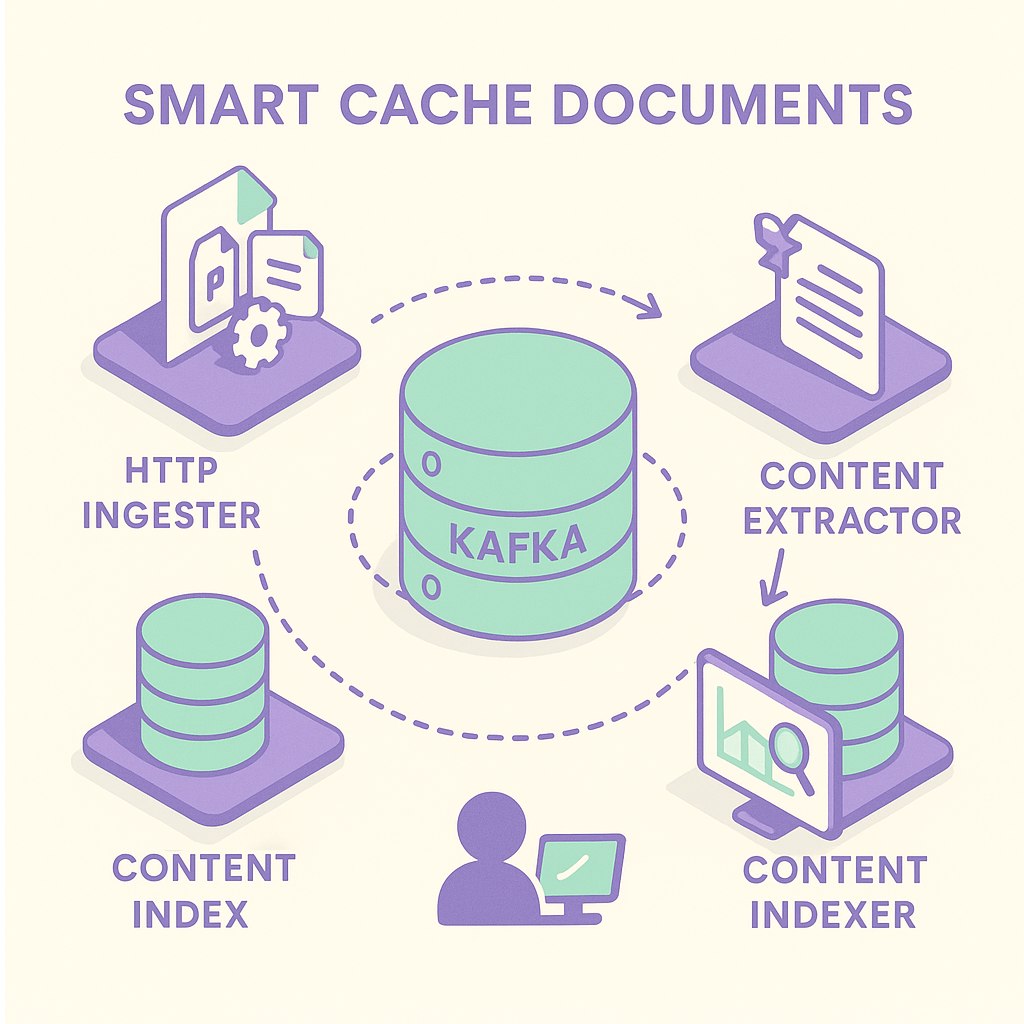
Smart-Cache DOCUMENTS is a secure document processing pipeline made up of three loosely coupled microservices to process documents.
Documents such as Microsoft Word or PDF files, enter the pipeline in one of two ways:
- As native files, uploaded to the HTTP Ingester microservice.
- Encoded as Base64 in a JSON message submitted directly to the Kafka topic from where the content will be extracted.
When a document reaches the end of the pipeline, its content, metadata and entities are indexed and searchable within Elasticsearch/OpenSearch.
Microservices
The three microservices which make up Smart Cache DOCUMENTS are described further in the sections below:
HTTP Ingester
The HTTP Ingester is a microservice that provides a REST endpoint for uploading native documents (e.g. Word, PDF) and their security labels to the pipeline. It supports multipart/form-data, so you can upload multiple files in a single request.
For each document, a unique URI is created using a configured namespace and a SHA-256 hash of the content. This guarantees that the same file always has the same URI. The document’s content is then read into a byte array, Base64 encoded, and packaged into a JSON message. This message which includes the URI, original filename and any relevant headers, is then sent a configured Kafka topic from where the content will be extracted. Included in the headers are the security labels that came with the document and these will passed along the pipeline.
Content Extractor
The Content Extractor is a microservice that reads messages from a configured Kafka topic for extarct requests. It then uses Apache Tika to get the text and other important metadata from the Base64-encoded document in each message and finally sends a message containing the extracted content and it’s security labels to another Kafka topic configured for extracted content.
Once the content has been extracted it may be picked up and processed by other microservices which feed back into this pipeline, for example, services to do entity extraction which can then be included in the indexed content. Alternatively it may be picked up and used elsewhere, such as to feed into knowledge extraction from where it will go into Smart Cache Graph.
Content Indexer
The Content Indexer is a microservice designed to read messages from the Kafka topic configured for extracted content. Its purpose is to use the data within these messages to build and then load a new document into the a document content index within Elasticsearch or OpenSearch, from where it is available to search queries.
API User Manual
Details on how to use the HTTP Ingester or Kafka API to upload documents are provided in the links below:
- HTTP Ingester API - upload multiple documents via HTTP
- Kafka API - submit documents direct to Kafka