Creating Knowledge
Knowledge graphs offer an effective way of structuring information about real-world things and the relationships between them. Building knowledge graphs that deliver real value require careful curation. The data they are created from needs to be of a high quality—ideally enriched and connected to other data within and/or outside an enterprise. This, combined with the need to standardize and map the data to a formal structure (i.e. an ontology), makes the process a significant undertaking. As a result, not all information ingested into CORE should end up in the Knowledge Graph. The goal should be to create knowledge only from high-value enterprise data—the kind that is retained long-term and whose quality and accuracy have a meaningful impact on business operations.
Knowledge graphs are both human-readable and machine-interpretable. They represent things (material or sometimes immaterial) as nodes and the relationships between them as edges. Knowledge graphs including the ones used in CORE are often developed using formal semantics such as RDF and ontologies.
RDF-based knowledge graphs offer a robust foundation for data integration, unification, linking, and reuse. They are expressive, standardized, and interoperable. The formal semantics of knowledge graphs is provided by ontologies such as IES4 and BFO (but there are others).
In Telicent CORE, knowledge graphs are created and pushed to the knowledge topic using an adapter or a mapper which are instantiated using telicent-lib. All knowledge graphs pushed to knowledge are stored as a single, unified graph in Smart-Cache GRAPH and indexed in Smart-Cache SEARCH.
How to create knowledge
Adapters and Mappers
Adapters and mappers are the main ETL components used for building data pipelines within CORE. These are instantiated using telicent-lib. CORE pipelines are usually made up of one adapter and n number of mappers.
Adapters are used to bring data into the platform, pushing that data to a single Kafka topic. This could be data that is already deemed as knowledge, and which is already “ontologized” and in RDF. However, in most cases adapters are used to bring in data in its most rawest of forms e.g. from a different system in your enterprise.

Mappers are then used to conduct ETL actions to bring data to the standard and quality expected of knowledge. Mappers read data from a single topic, conduct some form of ETL action prescribed using Python code and then push the resultant data onto a single topic. We normally recommend you use mappers in an atomic fashion i.e. conduct one ETL task per mapper for a given data set e.g. validate, cleanse, resolve, enrich, transform.
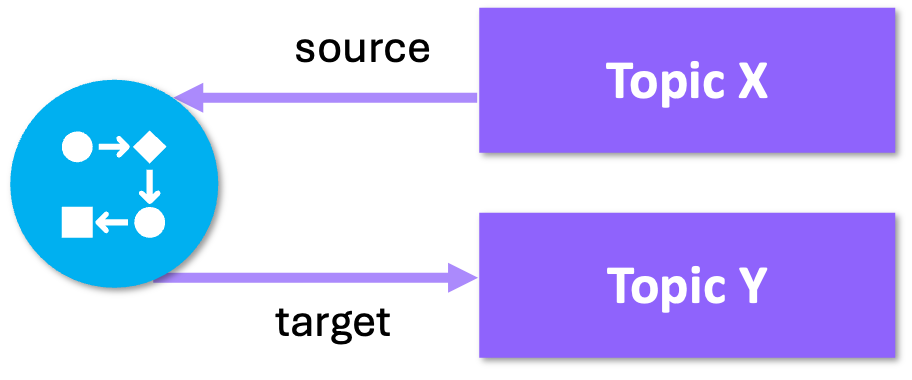
As mentioned previously, most CORE pipelines are made up of a single adapter and one or many mappers. The final mapper in a typical CORE pipeline chain, maps data to an ontology and RDF, the result of which is sent to the knowledge topic.
You can learn more about how to build adapters and mappers with telicent-lib here.
Working ontologies
Telicent CORE is ontology-agnostic, your knowledge graph can follow any schema, so long as you publish it as RDF to the knowledge topic. That said, we’ve found four-dimensional (4D) ontologies to be especially powerful for modeling the complexity of the world, capturing not just what things are and how they relate, but how they change over time. You can read more about the benefits of 4D here.
For organisations without a preferred ontology or those looking to avoid the often costly and time-consuming process of developing or selecting one, Telicent CORE, uses by default, the 4D ontology IES4. If you are new to IES4, we recommend reading the introduction document found here.
Complete mastery of the IES4 ontology is not required for creating IES4 compliant knowledge-we have built a Python library called telicent-ies-tool, which simplifies the process by abstracting much of the ontology’s complexity into straightforward Python classes and methods.
If you intend to use an ontology that is not IES4, we recommend using the most popular RDF library for Python, rdflib.
Custom ontologies and extensions
You can also create your own ontology or extensions to an ontology. You can find out more about creating ontology and adding extensions in the Creating Ontology section.
The basics of RDF
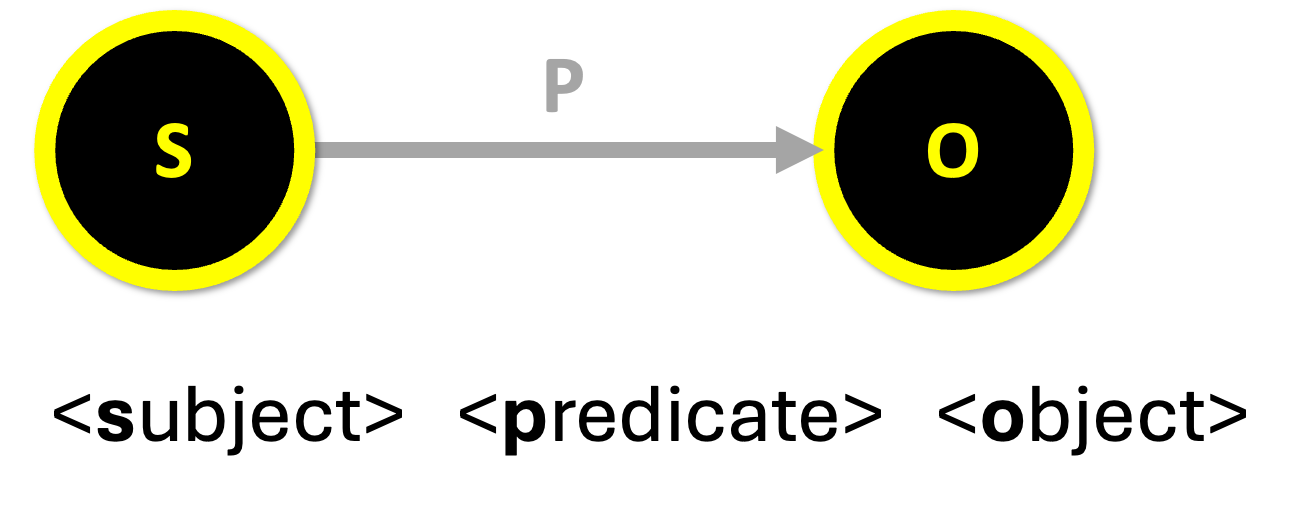
RDF, or Resource Description Framework, is a W3C standard that defines a simple yet flexible data model for structuring and exchanging information. RDF represents data as a series of three-part statements called triples, each consisting of a subject, a predicate, and an object. Together, these elements express a directional relationship: the subject is the source node, the predicate defines the nature of the relationship, and the object is the target node.
URIs
All nodes and edges in RDF are uniquely identified using Uniform Resource Identifiers (URIs). URIs act like a unique name or address for a resource in RDF. URIs provide the means of linking data about the same things e.g. persons, places, concepts, documents etc.
The first part of a URI string is known as the namespace. A namespace establishes a unique context for each thing in an RDF graph, helping to prevent naming conflicts across different domains. For example, the term “Bat” refers to a flying mammal in the context of animals, but in the context of sports, it refers to a piece of equipment. To ensure consistency and preserve the integrity of linked data, namespaces and URIs should remain stable and never change. This article, written by Sir Tim Berners-Lee, offers excellent guidance on creating well-structured URIs.
When selecting your own namespace for your data or ontology, choose a descriptive name and use a domain that you control (or one that is not already in use). All namespaces end with a separator which is either a / or a #.
Serializations of RDF
RDF can be serialized into various formats to accommodate different use cases and preferences. Common serializations include N-Triples .nt, which offers high performance due to its ease of parsing but can be storage-intensive, and Turtle (.ttl), which is more compact and human-readable, making it ideal for debugging and manual editing. Other formats like JSON-LD and RDF/XML formats are also available. While all these formats represent the same underlying RDF, they differ in syntax, readability, and application.
Most RDF libraries including rdflib and telicent-ies-tool provide methods to serialize a graph as RDF. Note that this needs to be reflected in the value provided in the Content-Type header of Kafka messages holding RDF in their payloads. This value must correspond to the official Media/MIME type for a given serialization e.g. if you are creating a knowledge message as turtle, then the the Content-Type must equal the MIME type, text/turtle.
End-to-end guide
For a full end-to-end guide-from getting data into Telicent CORE to creating knowledge, see here.